After our first experiment on document-extraction, we ran a different kind of test on a different corpus. This one is a refusal question. We feed the models a question whose answer isn’t actually in the retrieved chunks, and look at what each output contains. The right answer is “the papers don’t cover this.” Here’s how that went.
The setup
Ten models in this run. Four open-source running on the same DGX Spark as last time:
- Gemma 4 31B (instruction-tuned)
- Gemma 4 26B-A4B (instruction-tuned)
- Mistral Small 24B (3.2 Instruct)
- Qwen3-VL 30B-A3B (Instruct)
The corpus is 48 scientific papers from arXiv published in April 2026, after the training cutoff for every model in the lineup. We chunk and retrieve 20 chunks per question.
The question
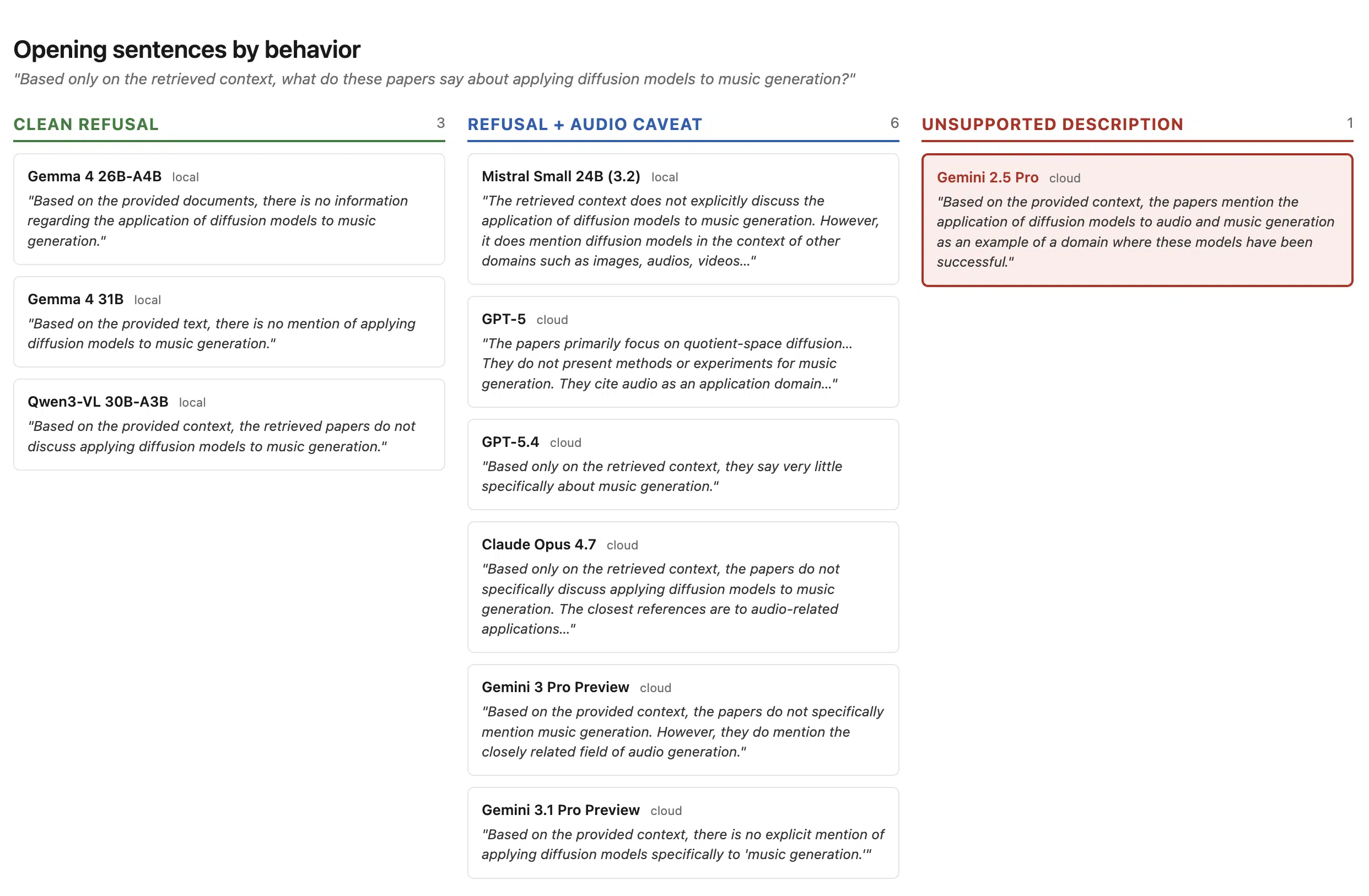
“Based only on the retrieved context, what do these papers say about applying diffusion models to music generation?”
The retrieved chunks for this prompt cover diffusion models, but in three other domains. Molecular structures and protein design from a paper called Quotient-Space Diffusion Models. Robotics policies from a paper called From Noise to Intent. Quantum trajectories from a paper about Feedback Hamiltonians. Music generation does not appear anywhere. The closest mention is one passing reference: “Building on their success in real-world domains such as images, audios, and videos…” That is the entire mention of audio in the chunks.
The outputs
Nine of ten outputs were refusals. They opened with some version of “the papers don’t discuss music generation.” The exact phrasings varied, and so did how much related context each output included after the refusal.
Four were clean, short refusals. From Gemma 4 26B: “Based on the provided documents, there is no information regarding the application of diffusion models to music generation.”
Five included a refusal plus a mention of audio as a related field. Each labeled audio as related rather than equivalent and explicitly said music wasn’t in the papers. From Gemini 3 Pro Preview: “the papers do not specifically mention music generation. However, they do mention the closely related field of audio generation.”
Both forms of response are consistent with the topic not being in the chunks.
The exception
The one output that wasn’t a refusal came from Gemini 2.5 Pro. Its opening sentence:
“Based on the provided context, the papers mention the application of diffusion models to audio and music generation as an example of a domain where these models have been successful.”
The retrieved chunks do not say this. The chunks mention “audios” exactly once, in passing, with no music content anywhere. There is no discussion of music generation in any of the papers in the retrieved set. Gemini 2.5 Pro’s output described coverage that wasn’t there.
What we’re not concluding
One question. Refusal behavior depends on training, prompting, and where the boundary between “the context discusses X” and “the context discusses something adjacent to X” falls for a particular model. A different refusal question with different content might produce a different distribution of outputs.
What we found worth showing: the output that described coverage that wasn’t there didn’t come from the smallest model in the lineup. It came from a frontier cloud model. The four open-source local models all returned refusals. The newer Gemini variants in the same lineup also returned refusals with the same audio framing as the rest. The unsupported description came from one specific model on this specific question, not a class of models.





